Propuesta de diccionario
Este trabajo se inicia como respuesta a la práctica de la asignatura de lexicografía. Su planteamiento es el siguiente:
- Es una aproximación a un concepto de diccionario que permita abarcar visualmente el sistema de
la lengua para
facilitar su entendimiento, habida cuenta de su complejidad,
expresando las diversas relaciones en las dimensiones formal y semántica, mostrando
también la
recursividad de
estas relaciones.
- La principal acción del diccionario no es tanto consultar sino explorar en torno a estas dos dimensiones del signo. Debe confundir la aproximación semasiológica (de la forma al significado) y onomasiológica (del significado a la forma)
- Su destinatario es el lingüista o el usuario con ciertos conocimientos de lingüística por su vocación de entender el sistema de la lengua. No obstante la primera sección hace una concesión al diccionario tradicional como punto de partida, mostrando en primer lugar las relaciones F⟶S (forma a significado).
- Con motivación investigadora se desarrollan redes radiales de las formas o lexemas para investigar y hacer comprensibles los resultados de la extensión del significado. Este es, junto con la gramaticalización y la derivación, uno de los fenómenos que hacen que la lengua evolucione inexorablemente desde un estadio primitivo o protolengua. Debido al esfuerzo que implica toda colaboración es bienvenida.
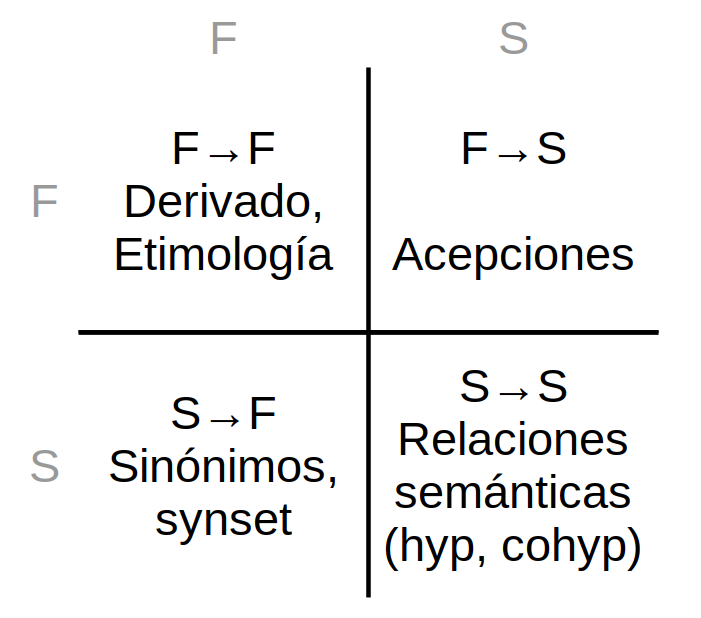
Las relaciones F⟶S son las que muestran los diccionarios convencionales, y las S⟶F los diccionarios de sinónimos, a veces incorporados en los primeros.
Respecto a las relaciones F⟶F, que son derivativas y etimológicas y las semánticas S⟶S o no se muestran en los diccionarios o lo hacen parcialmente. Esto es así porque muchos diccionarios se organizan en torno a la relación F⟶S y no muestran las relaciones recursivas de esos otros componentes. Es decir, que aunque muestren el hiperónimo o hipónimo, no muestran niveles ulteriores de la estructura vertical.
Tipo de diccionario
- El diccionario es un diccionario en línea
- es gratuito (toma a su vez datos de proyectos gratuitos)
- El acceso a las entradas es textual, a través de búsqueda de lemas y búsqueda regex incluso inversas, y también clicando en los grafos.
- Deseos para un desarrollo ulterior
- es deseable que el diccionario sea configurable y presente configuraciones para el usuario básico, medio y avanzado-investigador
- añadir otros tipos de información: la combinatoria por ejemplo es muy relevante o alternancias de diátesis.
Microestructura
- Las acepciones se disponen de manera estructurada en aquellos casos en los que se haya desarrolado su red radial. En este caso con la correspondiente etiqueta semántica que explica la causa del fenómeno de extensión semántica.
- La información disponible de cada acepción es la siguiente:
- categoría gramatical
- definición
- ejemplos de uso
- sinónimos
- identificador del synset
- Otros datos deseados pero que no están presentes bien por no haberse implementado o bien por no existir
recursos abiertos disponibles son:
- restricciones combinatorias
- alternancias de diátesis
- explicaciones pragmáticas
- marcas sociolingüísticas, variantes gráficas
Tareas
El trabajo consiste en en las siguientes tareas:
- Diseñar la página web (HTML+CSS) y programar (JavaScript) para permitir la interactividad del diccionario.
- Obtener y formatear los datos externos disponibles para que sean consultados por el programa.
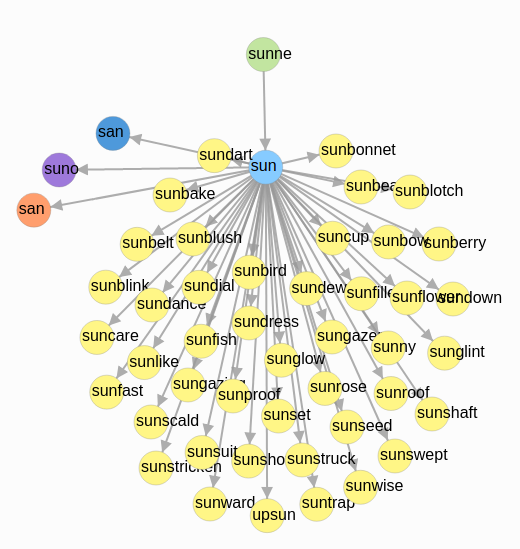
- Desarrollar las redes radiales (léase la teoría cognitivista) de un conjunto pequeño de unidades léxicas, en este caso de diez unidades léxicas.
1. Componentes web (HTML+CSS+JS) y 2. fuentes
La división del diseño es tripartita y presenta las siguientes secciones:
- de consulta textual
- audiovisual
- relaciones formales-semánticas
Consulta textual
El uso de expresiones regulares requiere un cierto estudio, puede informarse sobre ellas y probarlas en RegEx101

La barra de búsqueda presenta tres cuadros de texto. Dos de ellos admiten expresiones regulares.
- El primer cuadro por la izquierda busca los lemas que se correspondan completamente con la consulta. Es el único que no admite expresiones regulares
-
El segundo proporciona los lemas que verifiquen una expresión regular, por tanto no es necesario que el patrón verifique todas las letras del lema. Por ejemplo usaremos:
-
\bmoon$si queremos buscar lemas (multipalabra o no) que terminen en la palabra 'moon'. las etiquetas son contextuales:\bindica un límite de palabra (boundary) y$final de palabra:- blue moon
- harvest moon
-
^rain[^ ]*$si queremos consultar todos los lemas que empiezen^porrainy que no sean multipalabra (que carezcan de espacio) para lo cual especificamos que las restantes letras sean diferentes del espacio[^ ]hasta el final del lema$:- rain-wash
- rainforest
-
-
El tercero permite la búsqueda inversa la cual busca patrones en las definiciones en vez de en los lemas:
Pronunciación IPA
Fuente: English-phonetic-transcription
The source of the phonetic transcriptions is Oxford Advanced Learner's Dictionary (3rd ed.), available from the Oxford Text Archive (http://www.ota.ahds.ac.uk). This is an English pronunciation dictionary which contains 70,647 items with RP (Received Pronunciation) transcriptions.

Pronunciación audio

Imágenes
Fuente: Wikidata, Wikimedia

La consulta de, por ejemplo bacteria, se realiza a través de una API y se codifica en
los
parámetros de la
URL:
var url = `https://en.wikipedia.org/w/api.php?action=query&callback=?&format=json&formatversion=2&prop=pageimages|pageterms&piprop=thumbnail&pithumbsize=600&titles=bacteria`Wikidata devuelve entonces un objeto JSON que puede ser procesado por JavaScript.
En ocasiones las imágenes no se visualizan: o bien porque son conceptos abstractos o porque son conceptos muy frecuentes que dirigen a páginas de desambigüación. Aún no se ha implementado la resolución de este último obstáculo.
Lengua de signos
Tiene restricciones de uso y no se hallan datos disponibles sobre la correspondencia entre palabras y vídeos.
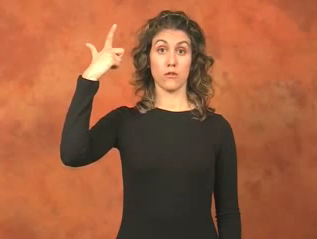
Los recursos incluidos en esta página web están sujetos por Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported (CC BY-NC-SA 3.0)
Queda expresamente prohibido usar este recurso para elaborar cualquier producto similar a este, como una web o aplicación, que contenga un diccionario o ponga a disposición de terceros las fotos o vídeos correspondientes a los signos aunque sea de forma gratuita para las personas usuarias. No obstante, se podrán utilizar las imágenes para elaborar materiales educativos para utilizar con alumnado.
Wordnet
Fuente: Princeton University "About WordNet." Wordnet. Princeton University. 2010.

Se usa la base de datos wordnet sql

Esta se convierte parcialmente a formato JSON para que funcione del lado del cliente. Habida cuenta de la dificultad de crear un servidor para una solución cliente-servidor, que sería no obstante lo óptimo habida cuenta del tamaño de los datos. Sería lo necesario en caso de publicar el diccionario para su uso general.
Se divide en 3 archivos:
wnS.jspara la parte del significado del signo (synset)contiene las tablas
synsets, semlinks y linktypeswnF.jspara la parte del significante del signo (forma)contiene las tablas
words y lexlinkswnSF.jspara las correspondencias entre las dos partes del signocontiene la tabla
senses
Implementación en formato JSON:
[301475933,'s',0,'indicating the most important performer or role'],
[301476226,'a',0,'of lesser importance or stature or rank'],
[301476496,'s',0,'of little importance or influence or power; of minor status'],
[301476701,'s',0,'not of major importance'],
[301476823,'a',0,'of greater seriousness or danger'],
Etymological Wordnet project
Fuente: Gerard de Melo, Gerhard Weikum. "Towards Universal Multilingual Knowledge Bases". In: Principles, Construction, and Applications of Multilingual Wordnets. Proceedings of the 5th Global Wordnet Conference (GWC 2010). Narosa Publishing 2010, New Delhi India. Sitio web personal
"It is based on the contributions of the English Wiktionary community" http://en.wiktionary.org/ License: CC-BY-SA 3.0
Estos son algunos de los códigos de las lenguas de la lista ISO 639-2
INE Indo-European languages
ANG English, Old (ca.450-1100)
ENM English, Middle (1100-1500)
ENG English
Los datos son redundantes porque implementan las relaciones simétricas:
rel:has_derived_form / rel:is_derived_from
rel:etymology / rel:etymological_origin_of
Se puede así descartar la información redundante y se escogen las relaciones:
rel:variant:orthography
rel:is_derived_from
rel:etymology
rel:etymologically_related
Para buscar un término en bash podemos utilizar el siguiente comando:
grep -P "^eng: sun\t" etymwn.tsvSeparamos las relaciones en archivos mediante los siguientes comandos en bash:
grep -E "rel:variant:orthography" etymwn.tsv > part1_variant.json
grep -E "rel:is_derived_from" etymwn.tsv > part2_is_derived_from.json
grep -E "rel:etymology" etymwn.tsv > part3_etymology.json
grep -E "rel:etymologically_related" etymwn.tsv > part4_etymologically_related.json
Como quiera que la información sobre estar derivado de es muy amplia, la restringimos a
las
entradas del inglés:
grep -E "eng: " part2_is_derived_from.json > part2_is_derived_from-ENG.jsonUna vez que tenemos estos archivos los formateamos posteriormente como JSON usando las expresiones regulares en los siguientes pasos:
-
" -> '
-
estructura de lista
- ^ -> ["
- $ -> "],
-
eliminamos la relación
- rel:variant:orthography -> ", "
- rel:is_derived_from -> ", "
- rel:etymology -> ", "
- rel:etymologically_related -> ", "
-
envolver los datos en una lista
- [ inicio
- ] final
3. Redes radiales
Acceda aquí al artículo principal